| .github | ||
| assets | ||
| lama_cleaner | ||
| .gitignore | ||
| Dockerfile | ||
| LICENSE | ||
| main.py | ||
| publish.sh | ||
| README.md | ||
| requirements-dev.txt | ||
| requirements.txt | ||
| setup.py | ||
Lama Cleaner
A free and open-source inpainting tool powered by SOTA AI model.

![]()

Features
- Completely free and open-source
- Fully self-hosted
- Classical image inpainting algorithm powered by cv2
- Multiple SOTA AI models
- Support CPU & GPU
- Various inpainting strategy
- Run as a desktop APP
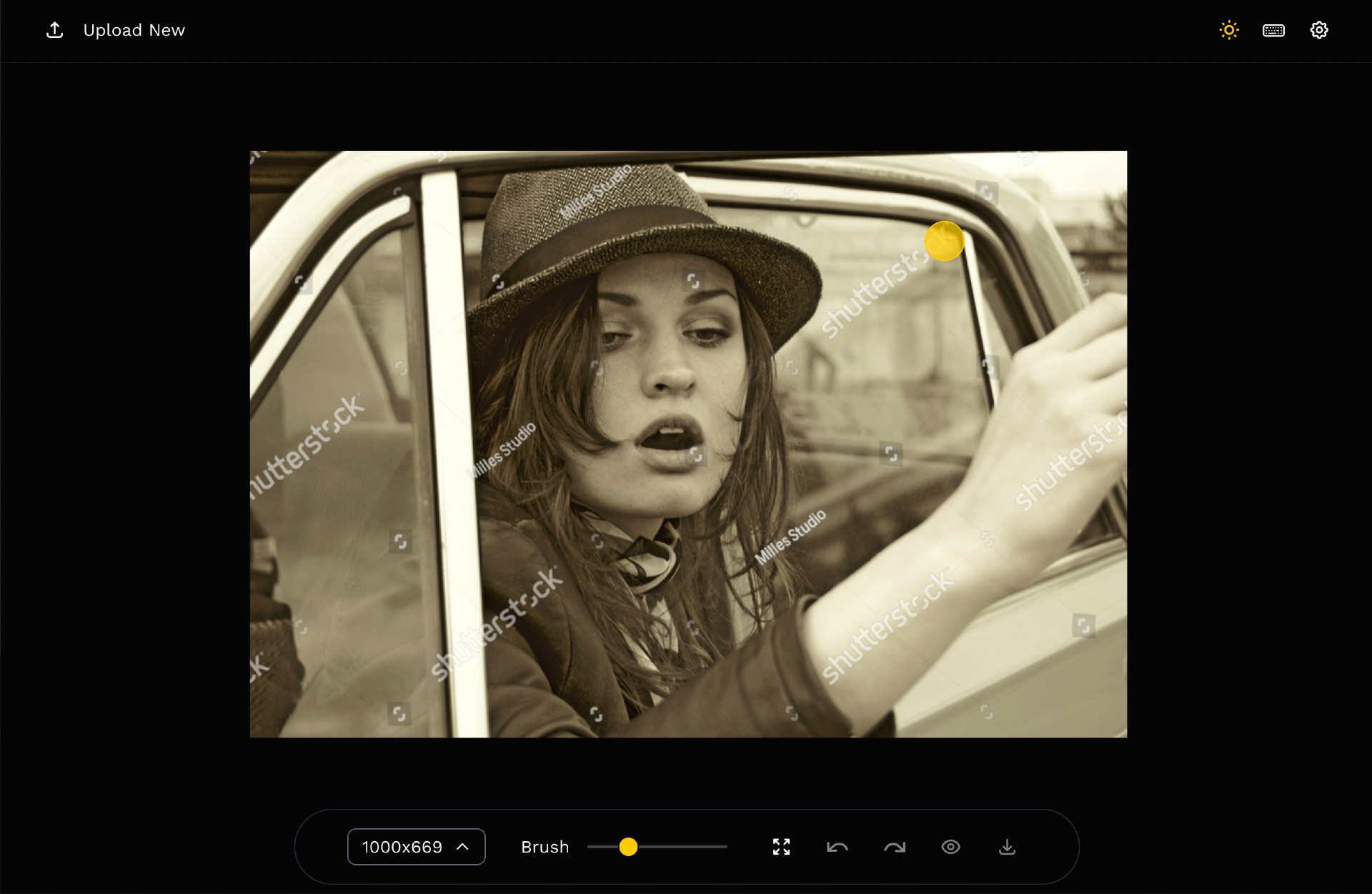
Usage
| Usage | Before | After |
|---|---|---|
| Remove unwanted things |  |
 |
| Remove unwanted person |  |
 |
| Remove Text |  |
 |
| Remove watermark |  |
 |
| Fix old photo |  |
 |
| Text Driven Inpainting |  |
Prompt: a fox sitting on a bench |
Quick Start
pip install lama-cleaner
# Model will be downloaded automatically
lama-cleaner --model=lama --device=cpu --port=8080
# Lama Cleaner is now running at http://localhost:8080
Available arguments:
| Name | Description | Default |
|---|---|---|
| --model | lama/ldm/zits/mat/fcf/sd. See details in Inpaint Model | lama |
| --hf_access_token | stable-diffusion(sd) model need huggingface access token https://huggingface.co/docs/hub/security-tokens | |
| --device | cuda or cpu | cuda |
| --port | Port for backend flask web server | 8080 |
| --gui | Launch lama-cleaner as a desktop application | |
| --gui_size | Set the window size for the application | 1200 900 |
| --input | Path to image you want to load by default | None |
| --debug | Enable debug mode for flask web server |
Inpainting Model
| Model | Description | Config |
|---|---|---|
| cv2 | 👍 No GPU is required, and for simple backgrounds, the results may even be better than AI models. | |
| LaMa | 👍 Generalizes well on high resolutions(~2k) |
|
| LDM | 👍 Possible to get better and more detail result 👍 The balance of time and quality can be achieved by adjusting steps 😐 Slower than GAN model 😐 Need more GPU memory |
Steps: You can get better result with large steps, but it will be more time-consuming Sampler: ddim or plms. In general plms can get better results with fewer steps |
| ZITS | 👍 Better holistic structures compared with previous methods 😐 Wireframe module is very slow on CPU |
Wireframe: Enable edge and line detect |
| MAT | TODO | |
| FcF | 👍 Better structure and texture generation 😐 Only support fixed size (512x512) input |
|
| SD1.4 | 👍 SOTA text-to-image diffusion model |
LaMa vs LDM
| Original Image | LaMa | LDM |
|---|---|---|
 |
 |
 |
LaMa vs ZITS
| Original Image | ZITS | LaMa |
|---|---|---|
 |
 |
 |
Image is from ZITS paper. I didn't find a good example to show the advantages of ZITS and let me know if you have a good example. There can also be possible problems with my code, if you find them, please let me know too!
LaMa vs FcF
| Original Image | Lama | FcF |
|---|---|---|
 |
 |
 |
Inpainting Strategy
Lama Cleaner provides three ways to run inpainting model on images, you can change it in the settings dialog.
| Strategy | Description | VRAM |
|---|---|---|
| Original | Use the resolution of the original image | 🎉 |
| Resize | Resize the image to a smaller size before inpainting. Lama Cleaner will make sure that the area of the image outside the mask is not degraded. | 🎉 🎉 |
| Crop | Crop masking area from the original image to do inpainting | 🎉 🎉 🎉 |
Download Model Mannually
If you have problems downloading the model automatically when lama-cleaner start,
you can download it manually. By default lama-cleaner will load model from TORCH_HOME=~/.cache/torch/hub/checkpoints/,
you can set TORCH_HOME to other folder and put the models there.
Development
Only needed if you plan to modify the frontend and recompile yourself.
Frontend
Frontend code are modified from cleanup.pictures, You can experience their great online services here.
- Install dependencies:
cd lama_cleaner/app/ && yarn - Start development server:
yarn start - Build:
yarn build
Docker
Run within a Docker container. Set the CACHE_DIR to models location path. Optionally add a -d option to
the docker run command below to run as a daemon.
Build Docker image
docker build -f Dockerfile -t lamacleaner .
Run Docker (cpu)
docker run -p 8080:8080 -e CACHE_DIR=/app/models -v $(pwd)/models:/app/models -v $(pwd):/app --rm lamacleaner \
python3 main.py --device=cpu --port=8080 --host=0.0.0.0
Run Docker (gpu)
docker run --gpus all -p 8080:8080 -e CACHE_DIR=/app/models -v $(pwd)/models:/app/models -v $(pwd):/app --rm lamacleaner \
python3 main.py --device=cuda --port=8080 --host=0.0.0.0
Then open http://localhost:8080